
Walk into any data science forum, any bootcamp Slack channel, any beginner community, and you will find some version of this question posted on a daily basis.
"I have a dataset with customer data. Should I use random forest or XGBoost?"
"My target variable is binary. Logistic regression or neural network?"
"We're trying to predict sales. What model do I build?"
These are not bad questions. They come from a genuine place of wanting to learn. But they reveal a habit that quietly limits a lot of junior analysts, and it is this: starting with the model instead of starting with the question.
The model you use is a consequence of the question you are trying to answer. Not the other way around. When you lead with the model, you are essentially picking up a tool before you know what you are building. Sometimes you get lucky. More often, you spend weeks building something that solves the wrong problem with the right technique.
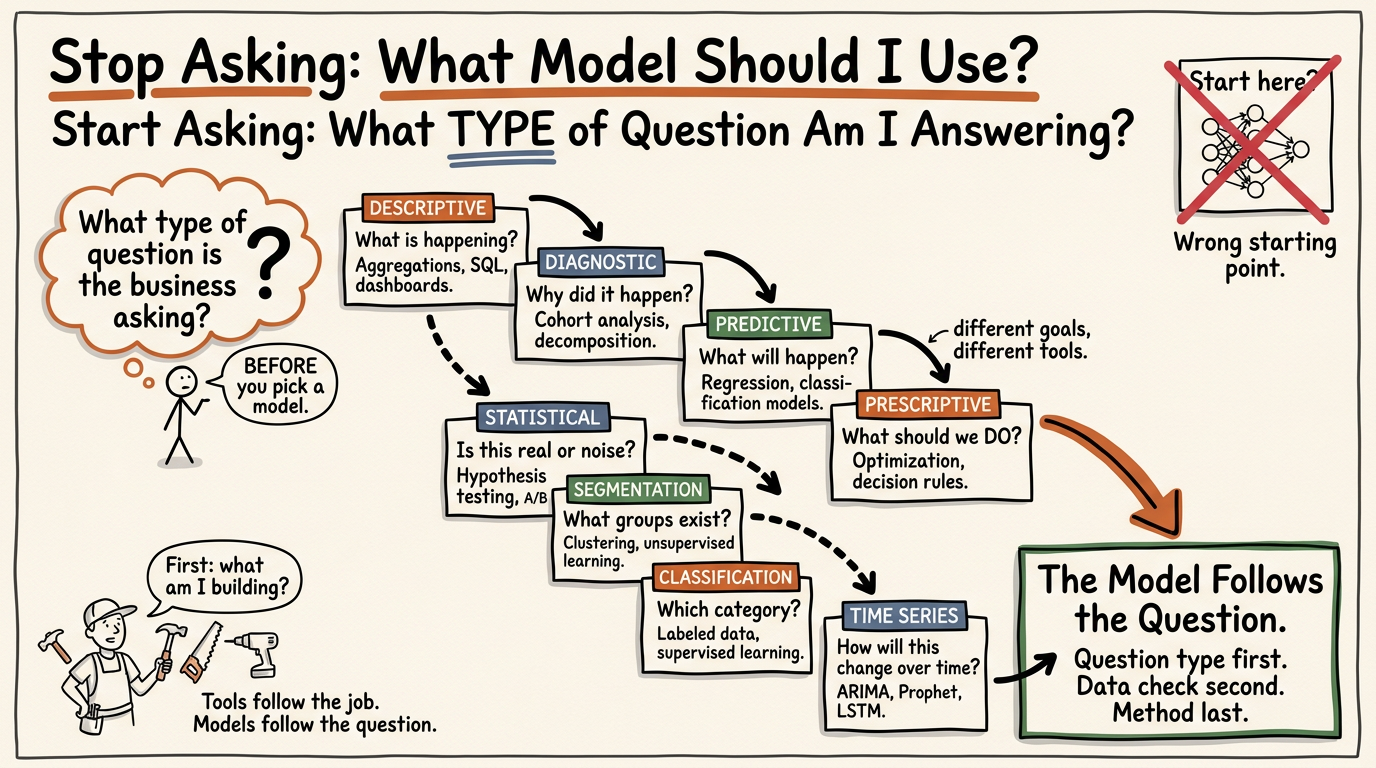
This article introduces the framework I use to break that habit. It is called the question type framework, and it maps eight distinct types of analytical questions to the methods best suited to answer them. Once you internalize this, the model choice becomes almost mechanical. The hard work shifts to where it belongs: figuring out what you are actually trying to answer.
The Core Idea: Questions Come Before Models
Here is the mental shift that changes everything.
Before you ask "what model should I use?", you need to ask "what type of question am I trying to answer?"
Every analytical question in a business context falls into one of eight categories. Each category has a natural family of methods that fit it. Some questions are about understanding what happened. Some are about understanding why. Some are about predicting what will happen next. Some are about deciding what to do.
These are fundamentally different questions. They require fundamentally different approaches. And confusing them is one of the most common sources of wasted effort in data science.
Here is the framework.
The Eight Question Types
1. Descriptive Questions
The question type: What is happening?
Descriptive questions are the foundation of any analysis. Before you can explain, predict, or prescribe anything, you need to describe the current state clearly. Descriptive analysis summarizes what exists in your data: volumes, distributions, averages, trends, and counts.
A business example: "How many customers did we acquire last quarter, and what was the average order value by region?"
This is not a modeling problem. This is a reporting and aggregation problem. The right tools are SQL, summary statistics, and well-designed dashboards. No algorithm required.
Where junior analysts go wrong: they reach for clustering or regression when a clear summary table would answer the question directly. Complexity is not a proxy for rigor. Sometimes the most valuable analytical output is a clean pivot table with the right segmentation.
The model family: aggregations, summary statistics, frequency tables, visualization.
2. Diagnostic Questions
The question type: Why did it happen?
Diagnostic questions go one level deeper. Something happened, and you want to understand the cause. Sales dropped in Q3. Churn spiked in a specific cohort. Conversion rate fell after a product change. Why?
A business example: "Why did customer retention drop 12% among users who signed up in January?"
Diagnostic analysis requires you to decompose a metric and isolate the driver. This is less about prediction and more about attribution. You are looking for the factor or combination of factors that explains the outcome.
The right tools here are cohort analysis, funnel breakdowns, contribution analysis, and in more advanced cases, causal inference techniques like difference-in-differences or regression discontinuity if you have a natural experiment.
Where junior analysts go wrong: they jump to predictive modeling when the real need is root cause investigation. A predictive model tells you what will happen next. It does not tell you why something already happened.
The model family: cohort analysis, decomposition trees, causal inference methods, correlation analysis with careful interpretation.
3. Predictive Questions
The question type: What will happen next?
This is the territory most data scientists feel most at home in, and it is often applied to problems that do not actually need it.
Predictive questions are appropriate when you have a future outcome you want to anticipate based on current signals. Will this customer churn in the next 30 days? Will this loan default? Will this user convert?
A business example: "Which of our current customers are most likely to cancel their subscription in the next 60 days?"
This is where regression, classification, gradient boosting, and similar supervised learning methods live. The model learns a relationship between input features and a target outcome, and it applies that relationship to new instances.
The critical prerequisite: you need a defined target variable, historical labeled examples, and a clear definition of what you are predicting and over what time horizon. Predictive modeling without a well-defined target is just complex pattern matching that does not answer anything.
The model family: logistic regression, decision trees, random forest, gradient boosting (XGBoost, LightGBM), neural networks for complex inputs.
4. Prescriptive Questions
The question type: What should we do?
Prescriptive questions are the most business-impactful and the least commonly taught. They go beyond predicting an outcome and directly recommend an action.
A business example: "Given what we know about each customer's likelihood to churn, what retention offer should we send them, and through which channel?"
Answering a prescriptive question requires not just a predictive model but a decision layer on top of it. You need to incorporate the cost of different actions, the constraints of what is operationally possible, and an optimization objective.
The right tools for prescriptive questions include optimization models, decision trees with business rules built in, reinforcement learning in more advanced contexts, and A/B tested policy frameworks.
Where junior analysts go wrong: they deliver a churn probability score and call the job done. The business does not need to know the probability. It needs to know what to do with it. If your output does not connect to an action, the prescriptive question has not been answered.
The model family: optimization, multi-armed bandits, reinforcement learning, decision rule engines, A/B testing frameworks.
5. Statistical Questions
The question type: Is this difference real, or is it noise?
Statistical questions are about inference. Did our pricing change actually increase revenue, or did it just look that way in a small sample? Is the difference between two groups meaningful, or within the range of random variation?
A business example: "Our new onboarding flow showed a 4% lift in activation rate during the test. Is that a real effect?"
This is hypothesis testing territory. The right tools are t-tests, chi-squared tests, ANOVA, and in business settings, proper A/B testing frameworks with power calculations done before the test runs.
One of the most overlooked skills in junior data science is knowing when a result is statistically meaningful versus when it just looks interesting in a chart. A model can tell you a feature is "important." A statistical test tells you whether that importance is likely to hold outside your training data.
Where junior analysts go wrong: they report observed differences without testing their significance, or they run tests without checking whether they had enough statistical power to detect a real effect in the first place.
The model family: hypothesis testing, confidence intervals, power analysis, A/B test frameworks, bootstrap resampling.
6. Segmentation Questions
The question type: What natural groups exist in this data?
Segmentation questions are about finding structure within a population. You are not predicting a known outcome. You are discovering unknown patterns in how entities differ from each other.
A business example: "Do our customers naturally fall into distinct behavioral groups that we could use to personalize our marketing strategy?"
This is clustering and unsupervised learning territory. K-means, hierarchical clustering, and DBSCAN are the common tools. Dimensionality reduction techniques like PCA or UMAP are often applied first to make the clustering more meaningful on high-dimensional data.
The important distinction: segmentation is exploratory by nature. You do not know the answer before you run the analysis. That makes it genuinely useful for discovery, but also genuinely dangerous if applied without clear business interpretation. A technically valid cluster solution that nobody can act on is not a useful segmentation.
Where junior analysts go wrong: they run clustering because someone asked them to "understand the customers better" without clarifying whether segmentation is actually the right tool for the question behind that request. Revisit the diagnostic and prescriptive question types before assuming segmentation is what is needed.
The model family: K-means, hierarchical clustering, DBSCAN, Gaussian mixture models, PCA, UMAP for visualization.
7. Classification Questions
The question type: Which category does this belong to?
Classification questions involve assigning a label to an instance based on its features. The label categories are known in advance. You are not discovering them, you are predicting them.
A business example: "Is this transaction fraudulent or legitimate?" or "Which of our three customer tiers does this new lead most closely resemble?"
The distinction from segmentation is critical. In classification, the categories are predefined and you have labeled training examples. In segmentation, the categories are unknown and you are discovering them from the data.
Most of the supervised learning toolkit lives here: logistic regression for binary outcomes, multinomial regression for multiple categories, decision trees, random forest, and gradient boosting. The choice among them depends on interpretability requirements, dataset size, and whether feature interactions matter.
Where junior analysts go wrong: they confuse classification with segmentation and vice versa. If you know the categories and have labeled examples, it is classification. If you are discovering the categories from unlabeled data, it is segmentation. The methods are completely different.
The model family: logistic regression, decision trees, random forest, gradient boosting, SVM, naive Bayes, neural networks for high-dimensional inputs.
8. Time Series Questions
The question type: How will this metric change over time?
Time series questions deal with data that has a temporal structure. The sequence matters. Yesterday's value carries information about today's, and today's carries information about tomorrow's. That autocorrelation structure makes standard regression models inappropriate.
A business example: "What will our daily active users look like over the next 90 days, accounting for weekly patterns and seasonal effects?"
Time series analysis requires methods that explicitly model temporal dependencies: trend, seasonality, and noise. Classical tools include ARIMA and its variants. More modern approaches include Facebook Prophet for business forecasting, and deep learning methods like LSTMs for complex multivariate time series.
Where junior analysts go wrong: they apply standard regression or random forest to time series data without accounting for the temporal structure, which creates data leakage and produces predictions that look good in training and fail completely in production.
The model family: ARIMA/SARIMA, exponential smoothing, Facebook Prophet, LSTM, temporal cross-validation frameworks.
The Decision Tree in Practice
Here is how to use this framework on any project. Before you open a notebook, answer these three questions in sequence.
First: What type of question is the business actually asking?
Map their request to one of the eight question types. If you are unsure, go back to the stakeholder and clarify. "Help us understand our customers" could be descriptive, diagnostic, or segmentation depending on what decision they are trying to support.
Second: Do I have what that question type requires?
Predictive questions need labeled historical data. Statistical questions need a clearly defined test design. Time series questions need temporal data with enough history to detect patterns. Check whether your data actually supports the question type before committing to an approach.
Third: What is the simplest method in that family that answers the question?
Start simple. A logistic regression that is interpretable and debuggable often serves a business better than an XGBoost model with marginally better AUC that nobody can explain. Complexity is only justified when simpler methods genuinely fall short.
That is the decision sequence. Question type first. Data requirements second. Method choice third.
The model is the last decision you make.
Practice This on Real Business Problems
DSBootcamp case studies are built around this exact framework. Every scenario on the platform presents a business situation first, and the analytical path flows from understanding what type of question the business is actually asking. If you want to sharpen your question-first thinking on real industry problems, that is the place to build it.